概覽
緊湊區塊中繼,BIP152,是一種減少傳播新區塊至全節點所需頻寬的方法。
摘要
當全節點之間共享許多相同的記憶池內容時,可以使用簡單的技術來減少傳播新區塊所需的頻寬。對等節點向接收對等節點傳送緊湊區塊「草圖」。這些草圖包含以下資訊:
- 新區塊的 80 位元組標頭
- 縮短的交易識別碼(txids),其設計目的是防止阻斷服務(DoS)攻擊
- 一些傳送對等節點預測接收對等節點尚未擁有的完整交易
接收對等節點接著嘗試使用收到的資訊和記憶體池中已有的交易來重建整個區塊。如果仍然缺少任何交易,它將從傳送對等節點請求這些交易。
這種方法的優點是,在最佳情況下,交易只需要傳送一次──即在它們最初廣播時──從而大幅減少整體頻寬。
此外,緊湊區塊中繼提議還提供了第二種營運模式(稱為高頻寬模式),接收節點要求其幾個對等節點直接傳送新區塊而不先請求許可,這可能會增加頻寬(因為兩個對等節點可能同時嘗試傳送同一個區塊),但進一步減少區塊到達高頻寬連線所需的時間(延遲)。
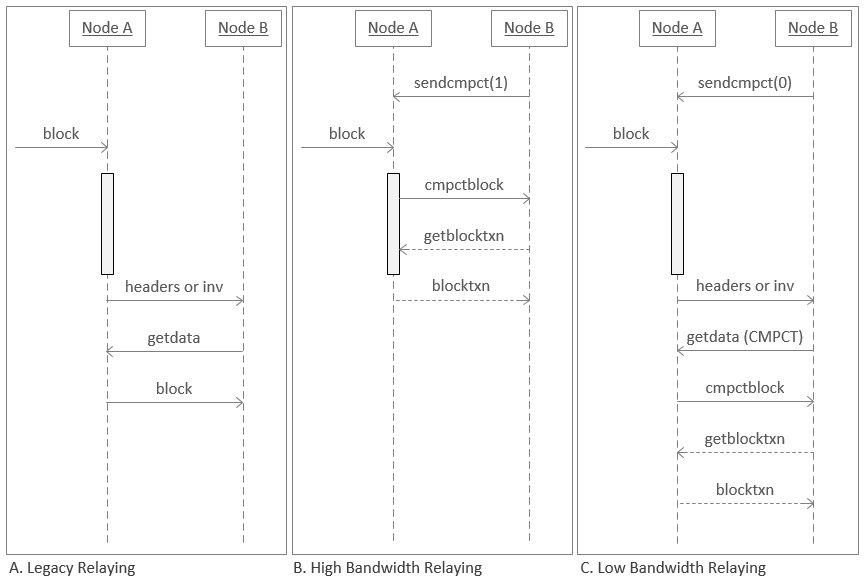
下圖顯示了節點目前傳送區塊的方式與緊湊區塊中繼的兩種營運模式的比較。節點 A 時間軸上的灰色方塊表示它正在執行驗證的期間。
-
在傳統中繼中,區塊經過節點 A 的驗證(灰色長條),然後向節點 B 傳送
inv訊息請求傳送區塊的許可。節點 B 回覆一個對區塊的請求(getdata),節點 A 傳送區塊。 -
在高頻寬中繼中,節點 B 使用
sendcmpt(1)(傳送緊湊)告訴節點 A 它希望盡快接收區塊。當新區塊到達時,節點 A 執行一些基本驗證(例如驗證區塊標頭),然後自動開始向節點 B 傳送標頭、縮短的 txids 和預測缺失的交易(如上所述)。節點 B 嘗試重建區塊並請求它仍然缺失的任何交易(getblocktxn),節點 A 傳送這些交易(blocktxn)。在背景中,兩個節點在將區塊新增到其本機區塊鏈副本之前完成對區塊的完整驗證,保持與之前相同的全節點安全性。 -
在低頻寬中繼中,節點 B 使用
sendcmpt(0)告訴節點 A 它希望盡可能減少頻寬使用。當新區塊到達時,節點 A 完全驗證它(因此它不會中繼任何無效區塊)。然後它詢問節點 B 是否想要該區塊(inv),這樣如果節點 B 已經從另一個對等節點接收到該區塊,它可以避免再次下載。如果節點 B 確實想要該區塊,它以緊湊模式請求它(getdata(CMPCT)),節點 A 傳送標頭、短 txids 和預測缺失的交易。節點 B 嘗試重建區塊,請求它仍然缺失的任何交易,節點 A 傳送這些交易。然後節點 B 正常完全驗證區塊。
一些有用的基準測試資料是什麼?
平均完整的 1MB 區塊公告可以由接收節點使用 9KB 的區塊草圖重建,加上接收節點記憶池中沒有的區塊中每個交易的額外開銷。見到的最大區塊草圖最高達到 20KB 以北的幾個位元組。
在「高頻寬」模式下執行即時實驗並讓節點預先填充最多 6 筆交易時,我們可以預期看到超過 90% 的區塊立即傳播而不需要請求任何缺失的交易。即使除了 coinbase 之外不預先填充任何交易,實驗顯示我們可以看到超過 60% 的區塊立即傳播,其餘需要完整的額外網路往返。
由於預熱節點的記憶池和區塊之間的差異很少超過 6 筆交易,這意味著緊湊區塊中繼實現了所需峰值頻寬的顯著減少。
如何選擇預期缺失的交易立即轉發?
為了減少初始實作中需要審查的內容,僅會預先傳送 coinbase 交易。
然而,在所描述的實驗中,傳送節點使用簡單的公式來選擇要傳送的交易:當節點 A 收到一個區塊時,它檢查哪些交易在區塊中但不在其記憶池中;這些是它預測其對等節點沒有的交易。理由是(在沒有額外資訊的情況下)你不知道的交易可能也是你的對等節點不知道的交易。使用這種基本啟發式方法,看到了很大的改進,說明許多時候最簡單的解決方案是最好的。
快速中繼網路如何與此相關?
快速中繼網路(FRN)由兩部分組成:
-
目前在快速中繼網路中精選的節點集合
-
快速區塊中繼協定(FBRP)
FRN 中精選的節點集合經過精心選擇,以全球最小中繼為首要優先事項。這些節點的故障將導致浪費算力的顯著增加和挖礦潛在的進一步集中化。今天絕大多數挖礦算力連線到這個網路。
原始的 FBRP 是參與節點如何相互通訊區塊資訊的方式。節點追蹤它們相互傳送的交易,並根據這些知識中繼區塊差異。對於一對一的伺服器-客戶端新區塊通訊,這個協定幾乎是最佳的。最近,一個基於 UDP 和前向錯誤更正(FEC)的協定,名為 RN-NextGeneration,已被部署供礦工測試和使用。然而,這些協定需要一個連線不良的中繼拓撲,並且比更通用的 p2p 網路更脆弱。使用緊湊區塊的協定層級改進將縮小精選節點網路和一般 p2p 網路之間的效能差距。p2p 網路的強韌性提升和整體區塊傳播速度將在網路未來發展中發揮作用。
這會擴展 Bitcoin 嗎?
此功能旨在節省節點的峰值區塊頻寬,減少可能降低終端使用者網際網路體驗的頻寬尖峰。然而,如以下影片所述,挖礦的集中化壓力在很大程度上是由於區塊傳播的延遲。緊湊區塊版本 1 主要不是為了解決該問題而設計的。
https://www.youtube.com/embed/Y6kibPzbrIc
預期礦工將繼續使用快速中繼網路,直到開發出更低延遲或更強韌的解決方案。然而,對基礎 p2p 協定的改進將在 FRN 故障的情況下增加強韌性,並且可能減少私有中繼網路的優勢,使它們不值得營運。
此外,使用第一版緊湊區塊進行的實驗和收集的資料將為我們預期與 FRN 更具競爭力的未來改進的設計提供資訊。
誰從緊湊區塊中受益?
-
想要中繼交易但網際網路頻寬有限的全節點使用者。如果您只是想在仍然向對等節點中繼區塊的同時節省最多頻寬,從 Bitcoin Core v0.12 開始已經有一個
blocksonly模式可用。僅區塊模式僅在交易包含在區塊中時接收交易,因此沒有額外的交易開銷。 -
整體網路。減少 p2p 網路上的區塊傳播時間可以創建一個更健康的網路,具有更好的基準中繼安全邊際。
編碼、測試、審查和部署緊湊區塊傳播的時程是什麼?
緊湊區塊的第一版已被分配 BIP152,有一個工作實作,並正在由開發者社群積極測試。
- BIP152: https://github.com/bitcoin/bips/blob/master/bip-0152.mediawiki
- 參考實作: https://github.com/bitcoin/bitcoin/pull/8068
如何調整這個以實現更快的 p2p 中繼?
可以對緊湊區塊方案進行額外的改進。這些與 RN-NG 相關,包含兩個方面:
-
首先,用 UDP 傳輸取代區塊資訊的 TCP 傳輸。
-
其次,使用前向錯誤更正(FEC)代碼處理丟失的封包並預先傳送缺失的交易資料。
UDP 傳輸允許伺服器傳送資料並由客戶端以路徑允許的速度消化,而不用擔心間歇性丟失的封包。客戶端寧願無序接收封包以盡快構建區塊,但 TCP 不允許這樣做。
為了處理丟失的封包和從多個伺服器接收非冗餘區塊資料,將採用 FEC 代碼。FEC 代碼是一種將原始資料轉換為冗餘代碼的方法,只要一定百分比的封包到達其目的地就允許無損傳輸,其中所需資料僅略大於資料的原始大小。
這將允許節點在接收到區塊時立即開始傳送區塊,並允許接收者重建同時從多個對等節點串流的區塊。所有這些工作都繼續建立在已經完成的緊湊區塊工作之上。這是一個中期擴展,開發正在進行中。
這個想法是新的嗎?
使用布隆過濾器(例如 BIP37 filteredblocks 中使用的)來更有效地傳輸區塊的想法在幾年前就被提出了。它也由 Pieter Wuille(sipa)在 2013 年實作,但他發現開銷使傳輸速度變慢。
[#bitcoin-dev, public log (excerpts)]
[2013-12-27]
09:12 < sipa> TD: i'm working on bip37-based block propagation
[...]
10:27 < BlueMatt> sipa: bip37 doesnt really make sense for block download, no? why do you want the filtered merkle tree instead of just the hash list (since you know you want all txn anyway)
[...]
15:14 < sipa> BlueMatt: the overhead of bip37 for full match is something like 1 bit per transaction, plus maybe 20 bytes per block or so
15:14 < sipa> over just sending the txid list
[2013-12-28]
00:11 < sipa> BlueMatt: i have a ~working bip37 block download branch, but it's buggy and seems to miss blocks and is very slow
00:15 < sipa> BlueMatt: haven't investigated, but my guess is transactions that a peer assumes we have and doesn't send again
00:15 < sipa> while they already have expired from our relay pool
[...]
00:17 < sipa> if we need to ask for missing transactions, there is an extra roundtrip, which makes it likely slower than full block download for many connections
00:18 < BlueMatt> you also cant request missing txn since they are no longer in mempool [...]
00:21 < gmaxwell> sounds like we really do need a protocol extension for this.
[...] 00:23 < sipa> gmaxwell: i don't see how to do it without extra roundtrip
00:23 < BlueMatt> send a list of txn in your mempool (or bloom filter over them or whatever)!如摘錄中所述,簡單地擴展協定以支援請求交易的個別交易雜湊以及區塊中的個別交易,最終允許緊湊區塊方案更簡單、抗 DoS 且更高效。
進一步閱讀資源
- https://people.xiph.org/~greg/efficient.block.xfer.txt
- https://people.xiph.org/~greg/lowlatency.block.xfer.txt
- https://people.xiph.org/~greg/weakblocks.txt
- https://people.xiph.org/~greg/mempool_sync_relay.txt
- https://en.bitcoin.it/wiki/User:Gmaxwell/block_network_coding
- http://diyhpl.us/~bryan/irc/bitcoin/block-propagation-links.2016-05-09.txt
- http://diyhpl.us/~bryan/irc/bitcoin/weak-blocks-links.2016-05-09.txt
- http://diyhpl.us/~bryan/irc/bitcoin/propagation-links.2016-05-09.txt